
【机器学习】集成学习代码练习(随机森林、GBDT、XGBoost、LightGBM等)
来源: 2022-12-26 23:42:05
本文是中国大学慕课《机器学习》的“集成学习”章节的课后代码。
课程地址:
https://www.icourse163.org/course/WZU-1464096179
(相关资料图)
课程完整代码:
https://github.com/fengdu78/WZU-machine-learning-course
代码修改并注释:黄海广,haiguang2000@wzu.edu.cn
importwarningswarnings.filterwarnings("ignore")importpandasaspdfromsklearn.model_selectionimporttrain_test_split生成数据 生成12000行的数据,训练集和测试集按照3:1划分
fromsklearn.datasetsimportmake_hastie_10_2data,target=make_hastie_10_2()
X_train,X_test,y_train,y_test=train_test_split(data,target,random_state=123)X_train.shape,X_test.shape
((9000, 10), (3000, 10))模型对比
对比六大模型,都使用默认参数
fromsklearn.linear_modelimportLogisticRegressionfromsklearn.ensembleimportRandomForestClassifierfromsklearn.ensembleimportAdaBoostClassifierfromsklearn.ensembleimportGradientBoostingClassifierfromxgboostimportXGBClassifierfromlightgbmimportLGBMClassifierfromsklearn.model_selectionimportcross_val_scoreimporttimeclf1=LogisticRegression()clf2=RandomForestClassifier()clf3=AdaBoostClassifier()clf4=GradientBoostingClassifier()clf5=XGBClassifier()clf6=LGBMClassifier()forclf,labelinzip([clf1,clf2,clf3,clf4,clf5,clf6],["LogisticRegression","RandomForest","AdaBoost","GBDT","XGBoost","LightGBM"]):start=time.time()scores=cross_val_score(clf,X_train,y_train,scoring="accuracy",cv=5)end=time.time()running_time=end-startprint("Accuracy:%0.8f (+/-%0.2f),耗时%0.2f秒。模型名称[%s]"%(scores.mean(),scores.std(),running_time,label))Accuracy: 0.47488889 (+/- 0.00),耗时0.04秒。模型名称[Logistic Regression]Accuracy: 0.88966667 (+/- 0.01),耗时16.34秒。模型名称[Random Forest]Accuracy: 0.88311111 (+/- 0.00),耗时3.39秒。模型名称[AdaBoost]Accuracy: 0.91388889 (+/- 0.01),耗时13.14秒。模型名称[GBDT]Accuracy: 0.92977778 (+/- 0.00),耗时3.60秒。模型名称[XGBoost]Accuracy: 0.93188889 (+/- 0.01),耗时0.58秒。模型名称[LightGBM]
对比了六大模型,可以看出,逻辑回归速度最快,但准确率最低。而LightGBM,速度快,而且准确率最高,所以,现在处理结构化数据的时候,大部分都是用LightGBM算法。
XGBoost的使用 1.原生XGBoost的使用importxgboostasxgb#记录程序运行时间importtimestart_time=time.time()#xgb矩阵赋值xgb_train=xgb.DMatrix(X_train,y_train)xgb_test=xgb.DMatrix(X_test,label=y_test)##参数params={"booster":"gbtree",#"silent":1,#设置成1则没有运行信息输出,最好是设置为0.#"nthread":7,#cpu线程数默认最大"eta":0.007,#如同学习率"min_child_weight":3,#这个参数默认是1,是每个叶子里面h的和至少是多少,对正负样本不均衡时的0-1分类而言#,假设 h 在0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100个样本。#这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。"max_depth":6,#构建树的深度,越大越容易过拟合"gamma":0.1,#树的叶子节点上作进一步分区所需的最小损失减少,越大越保守,一般0.1、0.2这样子。"subsample":0.7,#随机采样训练样本"colsample_bytree":0.7,#生成树时进行的列采样"lambda":2,#控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。#"alpha":0,#L1正则项参数#"scale_pos_weight":1, #如果取值大于0的话,在类别样本不平衡的情况下有助于快速收敛。#"objective":"multi:softmax",#多分类的问题#"num_class":10,#类别数,多分类与multisoftmax并用"seed":1000,#随机种子#"eval_metric":"auc"}plst=list(params.items())num_rounds=500#迭代次数watchlist=[(xgb_train,"train"),(xgb_test,"val")]#训练模型并保存#early_stopping_rounds当设置的迭代次数较大时,early_stopping_rounds可在一定的迭代次数内准确率没有提升就停止训练model=xgb.train(plst,xgb_train,num_rounds,watchlist,early_stopping_rounds=100,)#model.save_model("./model/xgb.model")#用于存储训练出的模型print("bestbest_ntree_limit",model.best_ntree_limit)y_pred=model.predict(xgb_test,ntree_limit=model.best_ntree_limit)print("error=%f"%(sum(1foriinrange(len(y_pred))ifint(y_pred[i]>0.5)!=y_test[i])/float(len(y_pred))))#输出运行时长cost_time=time.time()-start_timeprint("xgboostsuccess!","\n","costtime:",cost_time,"(s)......")[0]train-rmse:1.11000val-rmse:1.10422[1]train-rmse:1.10734val-rmse:1.10182[2]train-rmse:1.10465val-rmse:1.09932[3]train-rmse:1.10207val-rmse:1.09694
……
[497]train-rmse:0.62135val-rmse:0.68680[498]train-rmse:0.62096val-rmse:0.68650[499]train-rmse:0.62056val-rmse:0.68624best best_ntree_limit 500error=0.826667xgboost success! cost time: 3.5742645263671875 (s)......2.使用scikit-learn接口
会改变的函数名是:
eta -> learning_rate
lambda -> reg_lambda
alpha -> reg_alpha
fromsklearn.model_selectionimporttrain_test_splitfromsklearnimportmetricsfromxgboostimportXGBClassifierclf=XGBClassifier(# silent=0, #设置成1则没有运行信息输出,最好是设置为0.是否在运行升级时打印消息。#nthread=4,#cpu线程数默认最大learning_rate=0.3,#如同学习率min_child_weight=1,#这个参数默认是1,是每个叶子里面h的和至少是多少,对正负样本不均衡时的0-1分类而言#,假设 h 在0.01 附近,min_child_weight 为 1 意味着叶子节点中最少需要包含 100个样本。#这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该参数值越小,越容易 overfitting。max_depth=6,#构建树的深度,越大越容易过拟合gamma=0,#树的叶子节点上作进一步分区所需的最小损失减少,越大越保守,一般0.1、0.2这样子。subsample=1,#随机采样训练样本训练实例的子采样比max_delta_step=0,#最大增量步长,我们允许每个树的权重估计。colsample_bytree=1,#生成树时进行的列采样reg_lambda=1,#控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。#reg_alpha=0,#L1正则项参数#scale_pos_weight=1, #如果取值大于0的话,在类别样本不平衡的情况下有助于快速收敛。平衡正负权重#objective="multi:softmax",#多分类的问题指定学习任务和相应的学习目标#num_class=10,#类别数,多分类与multisoftmax并用n_estimators=100,#树的个数seed=1000#随机种子#eval_metric="auc")clf.fit(X_train,y_train)y_true,y_pred=y_test,clf.predict(X_test)print("Accuracy:%.4g"%metrics.accuracy_score(y_true,y_pred))Accuracy : 0.936LIghtGBM的使用 1.原生接口
importlightgbmaslgbfromsklearn.metricsimportmean_squared_error#加载你的数据#print("Loaddata...")#df_train=pd.read_csv("../regression/regression.train",header=None,sep="\t")#df_test=pd.read_csv("../regression/regression.test",header=None,sep="\t")##y_train=df_train[0].values#y_test=df_test[0].values#X_train=df_train.drop(0,axis=1).values#X_test=df_test.drop(0,axis=1).values#创建成lgb特征的数据集格式lgb_train=lgb.Dataset(X_train,y_train)#将数据保存到LightGBM二进制文件将使加载更快lgb_eval=lgb.Dataset(X_test,y_test,reference=lgb_train)#创建验证数据#将参数写成字典下形式params={"task":"train","boosting_type":"gbdt",#设置提升类型"objective":"regression",#目标函数"metric":{"l2","auc"},#评估函数"num_leaves":31,#叶子节点数"learning_rate":0.05,#学习速率"feature_fraction":0.9,#建树的特征选择比例"bagging_fraction":0.8,#建树的样本采样比例"bagging_freq":5,#k意味着每k次迭代执行bagging"verbose":1#<0显示致命的,=0显示错误(警告),>0显示信息}print("Starttraining...")#训练cvandtraingbm=lgb.train(params,lgb_train,num_boost_round=500,valid_sets=lgb_eval,early_stopping_rounds=5)#训练数据需要参数列表和数据集print("Savemodel...")gbm.save_model("model.txt")#训练后保存模型到文件print("Startpredicting...")#预测数据集y_pred=gbm.predict(X_test,num_iteration=gbm.best_iteration)#如果在训练期间启用了早期停止,可以通过best_iteration方式从最佳迭代中获得预测#评估模型print("error=%f"%(sum(1foriinrange(len(y_pred))ifint(y_pred[i]>0.5)!=y_test[i])/float(len(y_pred))))Start training...[LightGBM] [Warning] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000448 seconds.You can set `force_col_wise=true` to remove the overhead.[LightGBM] [Info] Total Bins 2550[LightGBM] [Info] Number of data points in the train set: 9000, number of used features: 10[LightGBM] [Info] Start training from score 0.012000[1]valid_0"s auc: 0.814399valid_0"s l2: 0.965563Training until validation scores don"t improve for 5 rounds[2]valid_0"s auc: 0.84729valid_0"s l2: 0.934647[3]valid_0"s auc: 0.872805valid_0"s l2: 0.905265[4]valid_0"s auc: 0.884117valid_0"s l2: 0.877875[5]valid_0"s auc: 0.895115valid_0"s l2: 0.852189
……
[191]valid_0"s auc: 0.982783valid_0"s l2: 0.319851[192]valid_0"s auc: 0.982751valid_0"s l2: 0.319971[193]valid_0"s auc: 0.982685valid_0"s l2: 0.320043Early stopping, best iteration is:[188]valid_0"s auc: 0.982794valid_0"s l2: 0.319746Save model...Start predicting...error=0.6640002.scikit-learn接口
fromsklearnimportmetricsfromlightgbmimportLGBMClassifierclf=LGBMClassifier(boosting_type="gbdt",#提升树的类型gbdt,dart,goss,rfnum_leaves=31,#树的最大叶子数,对比xgboost一般为2^(max_depth)max_depth=-1,#最大树的深度learning_rate=0.1,#学习率n_estimators=100,#拟合的树的棵树,相当于训练轮数subsample_for_bin=200000,objective=None,class_weight=None,min_split_gain=0.0,#最小分割增益min_child_weight=0.001,#分支结点的最小权重min_child_samples=20,subsample=1.0,#训练样本采样率行subsample_freq=0,#子样本频率colsample_bytree=1.0,#训练特征采样率列reg_alpha=0.0,#L1正则化系数reg_lambda=0.0,#L2正则化系数random_state=None,n_jobs=-1,silent=True,)clf.fit(X_train,y_train,eval_metric="auc")#设置验证集合verbose=False不打印过程clf.fit(X_train,y_train)y_true,y_pred=y_test,clf.predict(X_test)print("Accuracy:%.4g"%metrics.accuracy_score(y_true,y_pred))Accuracy : 0.927参考
1.https://xgboost.readthedocs.io/
2.https://lightgbm.readthedocs.io/
3.https://blog.csdn.net/q383700092/article/details/53763328?locationNum=9&fps=1
往期精彩回顾适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码
标签:
 查看更多滚动
查看更多滚动
2022-05-16
甘肃:“寒凉”持续盘踞 “甘味”农产备受考验

2022-05-16
(上海战疫录)专访上海一居民区书记:坚持!背后6000多居民等着我们

2022-05-16
西宁公安严厉打击涉疫违法犯罪 依法处理案件72起123人

2022-05-16
甘肃渭源:千年渭水文化蕴“写生热” 校地合作塑学生文化涵养

2022-05-16
5月16日起 西宁市部分区域有序开放
2022-05-16
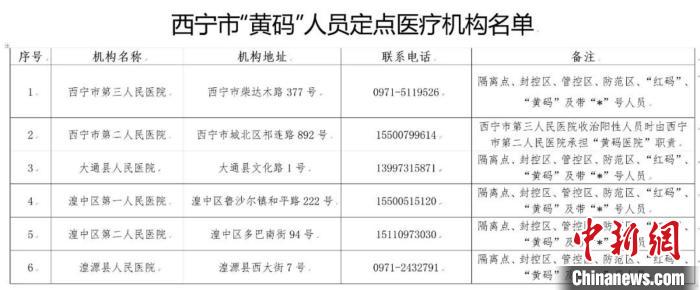
青海西宁:设置“黄码医院”保障重点人群医疗服务需求
- 12-26【机器学习】集成学习代码练习(随机森林、GBDT、XGBoost、LightGBM等)
- 12-26景泽环境(873478):2022年第三次临时股东大会决议
- 12-26每日冲煞属相 2023年9月29日属什么生肖冲什么 每日短讯
- 12-26焦点热议:国产大飞机新进展来了!12月26日起,全球首架C919开启验证飞行
- 12-25每日动态!国台办回应美国“2023财年国防授权法案”:强烈不满、坚决反对
- 12-24CBA官方:因用球砸裁判 齐麟被停赛2场+罚款15万元
- 12-23焦点关注:打干扰素可防治奥密克戎?专家:无科学依据,不推荐使用
- 12-23安正时尚(603839)12月23日主力资金净卖出55.59万元
- 12-23美媒预测2023年全球十大风险
- 12-22呈和科技: 关于参与投资基金的进展公告 天天热议
- 12-22美股异动 | ORIC制药(ORIC.US)盘后涨超60% 与辉瑞(PFE.US)达成合作并获股权投资
- 12-22华北制药董秘回复:公司将积极配合国家防疫政策有关要求,加紧安排布洛芬缓释胶囊等产品的生产_全球聚看点
- 12-21每日快讯!车e贷贷款逾期5000延迟还款会影响征信吗
- 12-21小辣椒与大理想 90后大学生“村官”在拼多多直播卖辣椒
- 12-21疫情之下,那些让“高端客户”买年金险的人,到底做对了什么?
- 12-20通宝能源: 山西通宝能源股份有限公司关于终止收购北京朗德金燕自动化装备股份有限公司55%股权暨关联交易的公告
- 12-20丰立智能:公司部分产品可应用到医疗器械领域
- 12-20天天快讯:12月19日基金净值:诺安双利债券发起最新净值2.605,跌0.34%
- 12-19中熔电气: 第三届董事会第五次会议决议公告:当前头条
- 12-19叮当钱包网贷逾期24年延迟还款会上征信系统吗
- 12-19天天微头条丨PIC16F170X/171X 8位单片机系列
- 12-18焦点热讯:金埔园林: 关于2023年度向银行及其它机构申请综合授信额度的公告
- 12-17美国FDA将于明年1月召开会议 考虑进一步更新新冠疫苗-世界今日报
- 12-17诈骗五万可以判多少年?是如何量刑的?_天天速读
- 12-16世界焦点!病毒的终极目的是什么?科学家给出清楚的答案
- 12-16涨停雷达:新冠治疗个股异动 新华制药触及涨停
- 12-16环球快资讯:独家:成都电信负责人更替 原绵阳电信总经理程洪开始主持工作
- 12-15大众设计主管明年1月1日离任 曾负责多款电动汽车设计 当前信息
- 12-15川仪股份董秘回复:公司将结合实际制定年度分红方案并及时履行信息披露义务_天天快消息
- 12-14头条焦点:美诺华: 宁波美诺华药业股份有限公司关于2021年股票期权与限制性股票激励计划首次授予股票期权第一个行权期行权条件及限制性股票第一个解除限售期解除限售条件成就的公告